
Jobs-to-be-Done Analysis: A Better-Than-Nothing Guide
As I’ve mentioned in my previous post on a DIY JTBD Workshop, there are a lot of great resources freely available on the web about Jobs-to-be-Done interviews. However, I’ve found a surprising lack of material on the analysis steps that ensue after that round of interviews. The Disruptive Voice podcast has an episode in which the debrief is explained roughly, but that’s as much as I could find until recently. That’s why I am going to share the steps we went through at store2be when doing a JTBD analysis project on “Why do brands hire Live Marketing?” from March to June 2020.
Interview Debrief
Over the course of around six weeks, we interviewed eight customers to figure out what caused them to reach for a live marketing campaign. During each interview, my research partner and I would both fill out a Forces of Progress diagram. In the debrief, we’d then compare notes and argue about our individual understanding of the forces we had noticed, and why we’d put them where we did. Quite often, I would hear something as a push, for example, and she’d hear it as a pull (or the other way around). It was in these discussions that I truly came to cherish doing this research as a team of two. Language is tricky, and having someone to go back and forth with on how something should be understood was invaluable.
Ultimately, the outcome of this step were eight Forces of Progress profiles – one for each interview. The forces were idiosyncratic, i.e. they were using language from the respective interview, for example. We purposefully did not try to abstract from what was actually said at this stage.
Affinitizing (and Coding) the Forces
Next, our goal was to compare and contrast stories – and the forces therein – with each other. I’ve heard Ryan Singer refer to this step as Affinitization or Forming Affinity Groups. After hearing Ryan talk through this process in a recent episode of his podcast Synthetic A Priori, I realize that our approach wasn’t “by the book”. However, we ended up pleased with the results, so I’ll still share what we did.
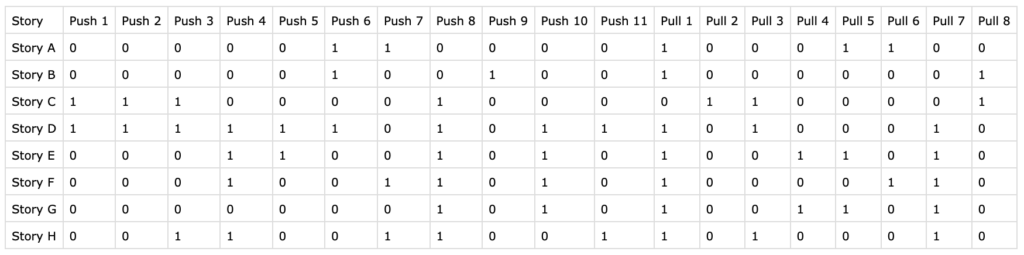
We were working off of a screenshot that Ryan shared a while back, which showed a spreadsheet containing different stories as rows and pushes and pulls as the columns. Any given cell in the spreadsheet would either be coded as 1 or 0, depending on whether a given push/pull was causal in that story or not.

Seeing this as our ultimate goal, we set up a new spreadsheet and started “importing” the stories one by one. The way we handled the Affinitization was iterative:
- We started by pasting the first story into the spreadsheet as-is, meaning that we did not abstract anything from the original phrasing of the forces. At the same time, we coded each cell as 1 for that particular story.
- Then, we copied over the second story and all of its pushes and pulls, while immediately starting to look for similarities between the new and old forces. Whenever two forces felt like they were describing the same thing, we’d not add a new column, but code the latest story with a 1 for that force and try to find a more abstract description for it.
- If a new story did introduce an entirely new force (=column), we’d go back and code all the stories already in the spreadsheet as 0.
I realize that this approach only ended up working because we had a manageable number of stories and forces – usually no more than three for any of the four forces per story, and mostly just one or two. The proper way – which Ryan describes here (jump to 12:35 on the recording) – would be to first get all of the forces across all of the stories out in the open (he actually suggests printing them on tiny strips of paper to be laid out on a tabletop), then look for similarities and finally find suitable titles once you’re satisfied with the groupings.
Cluster Analysis
After having coded all of the stories into a spreadsheet like the one shown above, the penultimate step in a Jobs-to-be-Done project is to identify which stories are closer together overall, and which are further apart. The goal here is to find clusters of similar stories. These clusters will be your Jobs.
With Ryan’s guidance (thank you!), we were able to run a cluster analysis using a hierarchical clustering approach and Ward’s method to measure cluster (dis)similarity.
I’ve put together an extremely basic web app using Shiny and R here, where you’ll be able to upload your spreadsheet (as a .csv file) and produce a dendrogram that shows how the stories are combined into fewer and fewer clusters.
You can use the following demo file to try for yourself:
The app should produce the following dendrogram:
(Don’t forget to select the right separator and quote symbols for your file – “Comma” and “None” in the case of the demo file)
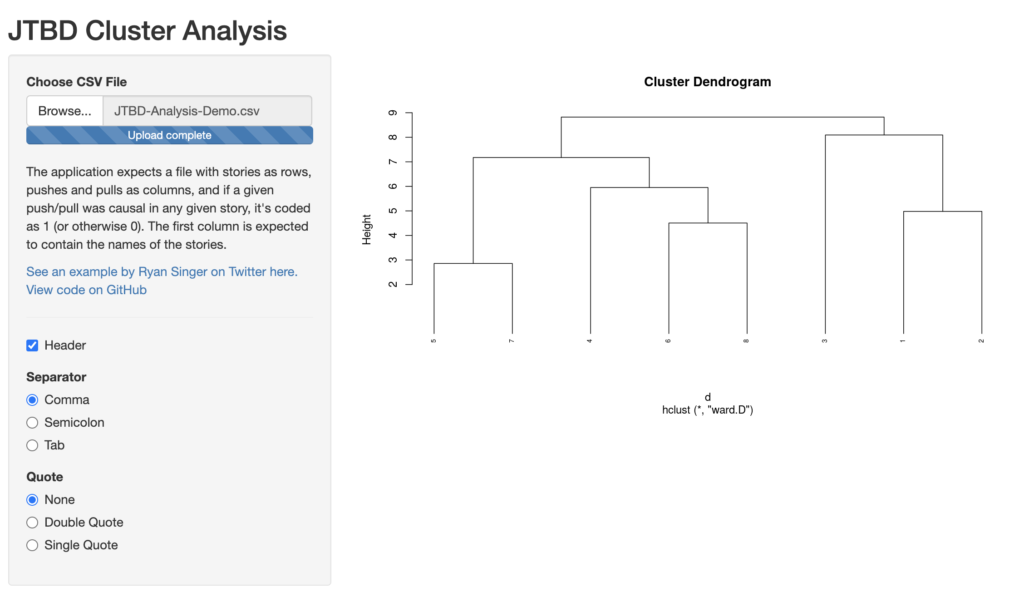
If you’re not yet familiar with how to read a dendrogram, it basically shows you how each of the stories were grouped together for each iteration of the clustering algorithm (read the image bottom-up). In the case of the demo file, you’ll see that stories 5 & 7 were combined first, then 6 & 8 and then 1 & 2. After that, story 4 was grouped in with 6 & 8 and that group is then combined with stories 5 & 7. In the second last step, story 3 is grouped with 1 & 2 before, theoretically, all stories are grouped into one big cluster in the very last step. The thing I like about this representation of the clustering process is the fact that it let’s you try to interpret different solutions and check how they feel in reality. This demo file is actually a redacted version of our original research and in our case, we ended up going with a three-cluster solution in the end, as it felt like it captured the essence of the stories best:
- Stories 5, 7, 4, 6 and 8 as a first cluster.
- Story 3 as a second cluster.
- Stories 1 and 2 as a third cluster.
Detailing the Jobs
The last step is that of detailing the Jobs. It includes defining the Job Statements that you see in the screenshot of Ryan’s analysis above. We, again, formed these together between my research partner and I, by discussing how the clusters share a distinct essence within them.
“When X, do Y so Z happens.”
Example format of a Job Statement.
The Job Statement usually consists of a context, solution and outcome, and we worked off of the following recording of a JTBD workshop by Bob Moesta (the video should start at 1:01:30):
In the end, we created a kind of canvas for each Job based on this slide that Bob briefly shows in the above workshop:
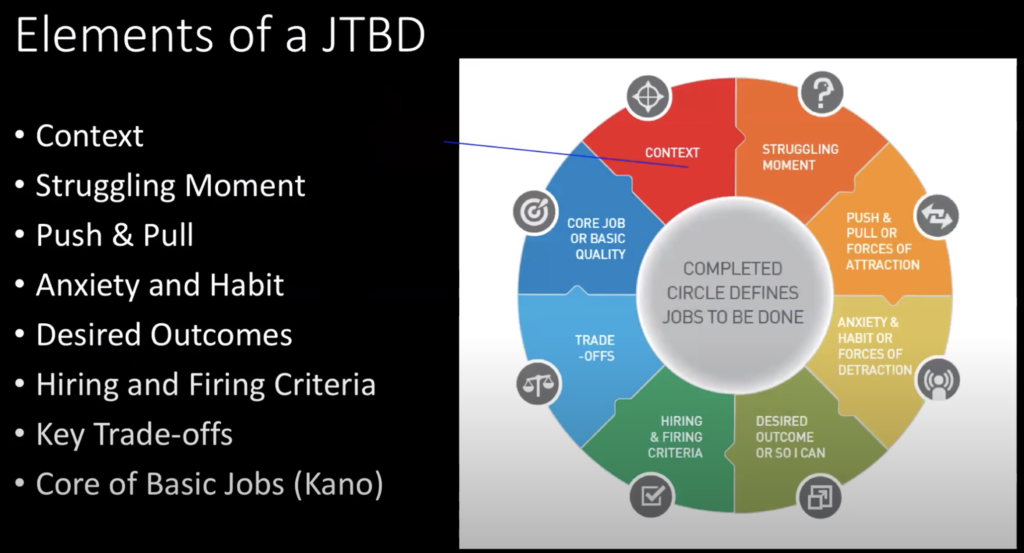
As we didn’t have much else to go on, we went a bit freestyle in the end and also included some notable quotes that we felt described each Job well. For future projects, I’m looking to be more rigorous in this area, and appreciate any resources that you can share with me!
I’m curious to hear if anyone else has gone through this full process and how you’ve distilled raw interview data into a detailed understanding of your customers’ Jobs-to-be-Done. For now, this post purposefully is a rough draft, so let me know which areas trigger questions or require more detail.
This is a fascinating article. Has your process changed at all since you last did this?
Hey Charles, thanks so much for your kind words!
I’ve had one more chance to do a “full-blown” JTBD research project since then, and at its core, we did the ananlysis exactly as described.
However, I was lucky to get to test an app specifically designed for JTBD analysis that Ryan is building. This made some steps a little easier, as well as enabled the team that worked with me to work self-sufficiently.
If you have specific questions for a JTBD research project that you might be working on, let me know! Would love to help in any way I can.
Thanks for sharing your process. What do you mean by Story? Ryan’s screenshot isn’t showing for me so I can’t see the example. I’m curious because I would think you’d want to know clusters of Forces, not Stories… Or am I misunderstanding what you mean by a Story?
Hey Hannah, sorry for being so slow to respond. “Story” in this context refers to “Interview”. His screenshot was more or less showing a table much like this one: https://signsofastruggle.net/wp-content/uploads/2020/08/image-1024×255.png
Each row is one interview, and then you “code” it with 0s and 1s as described, to then spot patterns across different interviews, where certain forces are more likely to go together, vs. other forces. Feel free to send me an email at david@shapers.builders if you want to discuss certain questions further!